Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Accessing the singleton can be done by using dependency injection.
In a class you can inject the IExamineManager interface:
In a view the IExamineManager can be injected as well:
This returns an active instance of the ExamineManager which exposes operations such as:
Default index & search providers
Full collection of index & search providers
All indexing and searching methods
Important to note that the Search methods on the ExamineManager will call the Search methods of the default search provider specified in config. If you want to search using a specific provider, there are generally two approaches for this.
If you want to use the searcher of a specific index, you should get the the searcher via the index:
If you have configured a custom searcher that you wish to use instead, you can access the searcher directly via the IExamineManager instance:
An example using a custom searcher is below:
When you wanna populate an index, you will need to use the IExamineManager and get the specific index. The build-in index names are all available as constants from the Umbraco.Cms.Core.Constants.UmbracoIndexes namespace
The indexing methods available on a single index are:
Provides an overview of the available Examine functionality available directly within the Umbraco backoffice
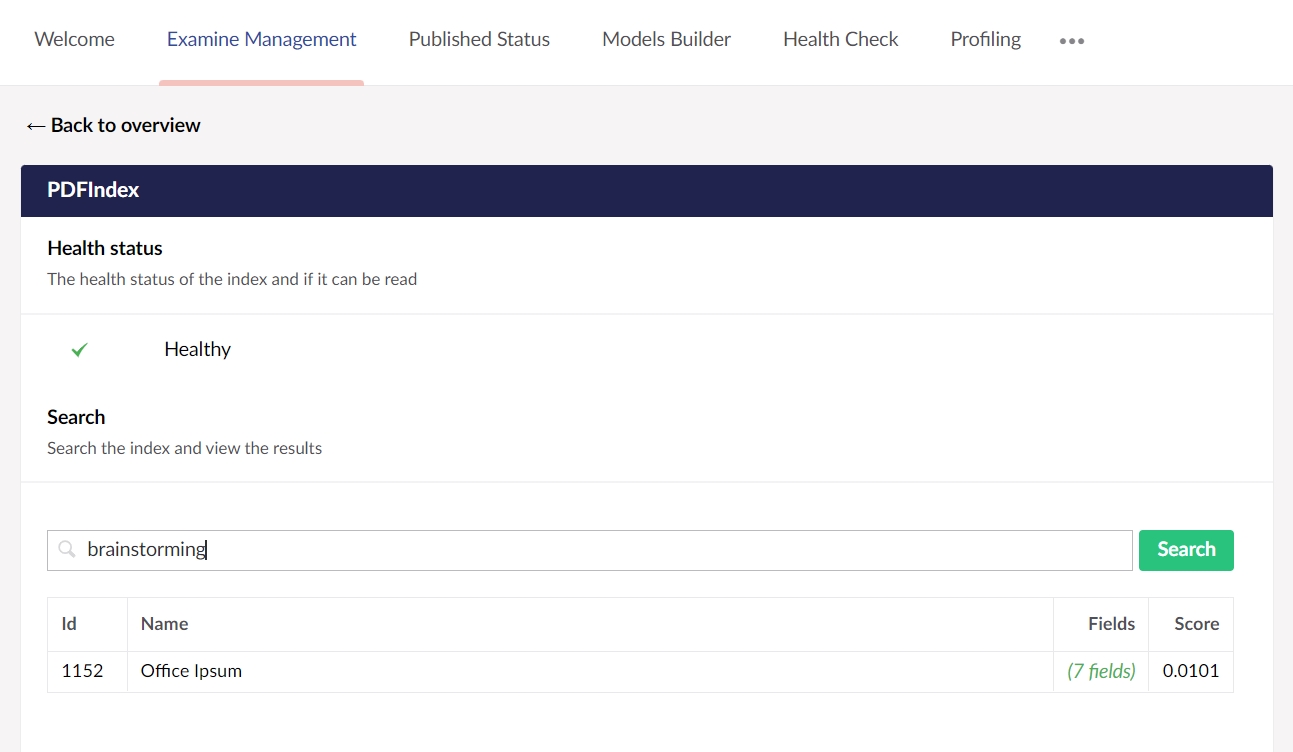
The Umbraco backoffice allows you to view details about your Examine indexes and searchers - all in one place. You can see which fields are being indexed, rebuild the indexes if there's a problem, and test keywords to see what results would be returned.
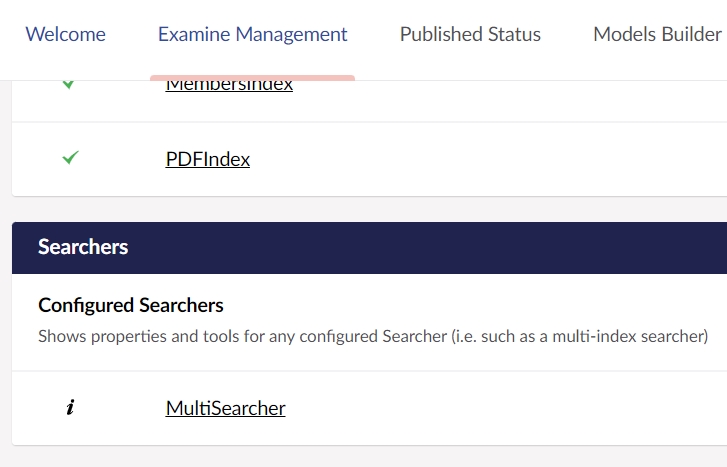
The Examine Management section, accessible from within the Settings section, is split into two sections: Indexers and Searchers.
From the Indexers section, you can view details about each Examine index currently configured within your Umbraco installation. Clicking any of these indexes will show you additional options, each discussed below.
This section allows you to see the list of properties on the index that you selected, including how many documents and fields are currently being stored.
Within the Indexers it displays the details for the index provider as well.
This can be useful to confirm the configuration that Umbraco is using and to ensure it is working as expected. This section also displays the full file path of the index itself.
This section also provides the ability to rebuild the index, should this be required. Depending on how much content your website has, rebuilding the search indexes could take a while and affect the site performance temporarily, so it is not recommended to do this while the website is under high load.
From here you can see the default system fields that are stored for each document within the search index. That includes the number of fields document, and the score which is calculated by Examine depending on how closely the individual results matched the search term.
From the Searchers section, you can view details about each Examine searcher currently configured within your Umbraco installation. Clicking any of these searchers will take you to a search page, where you can test out your search terms.
You can see an example here how to configure an Examine searcher in the Examine Multisearcher documentation.
The search field allows you to enter a search term and receive results back from the searcher in question. You can confirm if your query is working as expected. Matching results are returned in their raw format, with the score, document ID and Name being returned. The score is calculated by Examine depending on how closely the individual results matched the search term.
Search in Umbraco is powered by Examine out of the box, which is a Lucene-based search and index engine for Umbraco. Umbraco provides everything required to have powerful and fast search up and running on your website. You can also extend or replace the available configuration to exactly match your requirements. This documentation focuses on the Examine implementation.
Understand how Examine works and walk through the many available options and settings in Umbraco.
This guide will help you get set up quickly using Examine with minimal configuration options. Umbraco ships Examine with 3 indexes: internal, external, and members. The internal index should not be used for searching when returning results on a public website because it includes content that has not been published yet. Instead, you can use the external index to get up and running.
In the coming examples, the Umbraco Starter Kit has been used, as it provides some example content that can be searched. Therefore, some of the examples below may require 'the setting up of templates, etc' if you follow the guide on your existing site.
The starter kit comes with some Templates, Document Types, and content nodes created already. We will use some of these to set up a basic search system. This is a 'Quick Start' guide, as many more complex searches are possible with Examine.
We will make it possible to 'search' on the People page, by adding a search bar to the template page: people.cshtml - add the following form at the top of the template, but underneath the <nav> element:
This will create a basic input field at the top of the page and make it post to the same people page when submitted along with the search term.
The best practice for POST requests is to encapsulate the request handling in a controller. To do this we will leverage the concept of route hijacking.
Let's start by creating a PeopleController that derives from RenderController and add an Index method.
It is important to name our controller by the convention NameOfViewController. In our case the view is named People, so the controller is named PeopleController.
To search anything from our controller, we first need to create a service that handles the actual search logic. We'll start by creating an interface for our service.
Now create a default implementation of the service interface.
And finally register the service in Startup.
To perform the search we will first need to get a reference to the particular Examine index that we want to search. Then we will use this index to access its corresponding Searcher. We use the Searcher to construct the query logic to execute and search the index.
Umbraco ships with three indexes:
ExternalIndex - available to use for indexing published unprotected content.
InternalIndex - which Umbraco's backoffice search uses.
MembersIndex - which Umbraco's Membership implementation uses.
You can create your own indexes too if you need to analyse text in a different language for example.
The service IExamineManager is used to retrieve an Examine index by its 'alias', so we need to inject that service into our SearchService.
With the IExamineManager injected in our SearchService, we can implement the SearchContentNames method. We do this using the Searcher for the Examine index 'ExternalIndex'.
We reference the External index by its alias "ExternalIndex". Umbraco has a set of 'Constants' that refer to the indexes that can be more convenient to use Constants.UmbracoIndexes. So, in the example here we could have used Constants.UmbracoIndexes.ExternalIndexName instead of "ExternalIndex".
The Searcher has a CreateQuery method, where you can choose to search content, media or members eg:
From here you can see how we can chain together the logic to perform the search. In the example, we are searching all content using the person Document Type, where the nodeName is equal to the search term that was typed in the input bar.
Calling .Execute() at the end of the query logic triggers the search and returns a set of matching search results, which we can loop through to get the IDs of the resulting content items.
We want to retrieve the actual content from the IDs. For that, we need the UmbracoHelper, which must be injected into our service as well. The final implementation of SearchService then looks like this.
After getting the ids from our search, we then loop through the list and return the content.
We will now need a custom view model so that we can pass our search results to the view. Our view model needs to inherit from PublishedContentWrapped because our People view is expecting a model that is content. We then wrap the content and add the search data, all in a convenient view model.
Now that we've created our service to handle the actual search logic, and our view model to pass the search results to the view, let's look at using them in the controller. We will want to update the Index() method to get out the query string from the request, then create a view model and populate the SearchResults property by using our service.
The final thing we need to do is update the view to use our new view model. We do that by changing the @inherits line in the view.
Let's now use the view model to display the search results. We'll place them directly under the form we created earlier.
Examine has a lot of different ways to query data. Building upon the example from before, here are a few other searches that can be done to get different data:
Let's say you want to search through all content nodes by their file names. You could amend the query from before like this:
To do the search like above, but only use Lucene to query, amend the query from before like this:
To search through all child nodes of a specific node by their bodyText property, amend the query from before like this:
Examine uses Lucene as its search and index engine. Searching using Examine with Lucene can be powerful and fast.
The Examine documentation is found here https://shazwazza.github.io/Examine/ and the source code repository for Examine is here https://github.com/Shazwazza/Examine.
Examine allows you to index and search data quickly. Examine is a library that sits on top of Lucene.Net, a high-performance search engine library. Examine provides APIs to make searching and indexing as straightforward as possible. UmbracoExamine adds an extra layer to access Umbraco-specific APIs for indexing and searching content and media.
Examine is provider based so it is extensible and allows you to configure your own custom indexes if required. The backoffice search in Umbraco also uses this same search engine, so you can trust that you're in good hands.
Get up and running with Examine straight away with this quick start guide.
Learn how to customize the built in Umbraco indexes and how to create your own Lucene indexes using Examine in Umbraco.
Learn how to index PDF files in Examine and how to create a multisearcher that searches through both the External Index and the Pdf Index.
Provides an overview of the available Examine functionality available directly within the Umbraco backoffice.
Details about subscribing to Examine events which can provide a way to modify the data being indexed.
Describes the singleton object which exposes all of the index and search providers which are registered in the configuration of the Umbraco application.
Learn how to build and customize the indexes that comes with your Umbraco website.
You can modify the built-in indexes in the following ways:
Events - giving you control over exactly what data goes into them and how the fields are configured
Changing the field value types to change how values are stored in the index
Changing the IValueSetValidator to change what goes into the index
Take control of the entire index creation pipeline to change the implementation
We can do all this by using the ConfigureNamedOptions pattern.
We will start by creating a ConfigureExamineOptions class, that derives from IConfigureNamedOptions<LuceneDirectoryIndexOptions>:
In this sample we are altering the external index and thus we name the class ConfigureExternalIndexOptions. If you are altering multiple indexes, it is recommended to have separate classes for each index - i.e. ConfigureExternalIndexOptions for the external index, ConfigureInternalIndexOptions for the internal index and so on.
When using the ConfigureNamedOptions pattern, we have to register this in a composer for it to configure our indexes, this can be done like this:
By default, Examine will store values into the Lucene index as "Full Text" fields, meaning the values will be indexed and analyzed for a textual search. However, if a field value is numerical, date/time, or another non-textual value type, you might want to change how the value is stored in the index. This will let you take advantage of some value type-specific search features such as numerical or date range.
There is some documentation about this in the Examine documentation.
The easiest way to modify how a field is configured is using the ConfigureNamedOptions pattern like so:
This will ensure that the price field in the index is treated as a double type (if the price field does not exist in the index, it is added).
An IValueSetValidator is responsible for validating a ValueSet to see if it should be included in the index. For example, by default the validation process for the ExternalIndex checks if a ValueSet has a category type of either "media" or "content" (not member). If a ValueSet was passed to the ExternalIndex and it did not pass this requirement it would be ignored.
The IValueSetValidator is also responsible for filtering the data in the ValueSet. For example, by default the validator for the MemberIndex will validate on all the default member properties, so an extra property "PhoneNumber", would not pass validation, and therefore not be included.
The IValueSetValidator implementation for the built-in indexes, can be changed like this:
Remember to register ConfigureMemberIndexOptions in your composer.
The following example will show how to create an index that will only include nodes based on the document type product.
We always recommend that you use the existing built in ExternalIndex. You should then query based on the NodeTypeAlias instead of creating a new separate index based on that particular node type. However, should the need arise, the example below will show you how to do it.
Take a look at our Examine Quick Start to see some examples of how to search the ExternalIndex.
To create this index we need five things:
An UmbracoExamineIndex implementation that defines the index.
An IConfigureNamedOptions implementation that configures the index fields and options.
An IValueSetBuilder implementation that builds index value sets a piece of content.
An IndexPopulator implementation that populates the index with the value sets for all applicable content.
An INotificationHandler implementation that updates the index when content changes.
A composer that adds all these services to the runtime.
This is only an example of how you could do indexing. In this example, we're indexing all content, both published and unpublished.
In certain scenarios only published content should be added to the index. To achieve that, you will need to implement your own logic to filter out unpublished content. This can be somewhat tricky as the published state can vary throughout an entire structure of content nodes in the content tree. For inspiration on how to go about such filtering, you can look at the ContentIndexPopulator in Umbraco.
The index will only update its content when you manually trigger an index rebuild in the Examine dashboard. This is not always the desired behavior for a custom index.
To update your index when content changes, you can use notification handlers.
The following handler class does not automatically update the descendant items of the modified content nodes, such as removing descendants of deleted content. If changes to the parent content item can affect its children or descendant items in your setup, please refer to the UmbracoContentIndex.PerformDeleteFromIndex() in Umbraco. Such logic should be applied when both removing and reindexing content items of type product.
You can find further inspiration for implementing notification handlers (for example, for media updates) in the UmbracoExamine.PDF package.
The order of these registrations matters. It is important to register your index with AddExamineLuceneIndex before calling ConfigureOptions.
If you want to index PDF files and search for them you will need to use the UmbracoExamine.Pdf extension package.
Install with NuGet: dotnet add package Umbraco.ExaminePDF
This will create a new Examine index called "PDFIndex", which will appear in "Examine Management" dashboard under the "Settings" section. Using this index you can start searching the contents of any PDF files uploaded to the media section.
A multi-index searcher is a searcher that can search multiple indexes. This can be helpful when you for example want to search both the external and internal indexes. You can register a multi-index searcher with the ExamineManager on startup like:
With this approach, the multi-index searcher will show up in the "Examine Management" dashboard.
The multi-index searcher can be resolved in code from the ExamineManager like this:
The implementation of IPdfTextExtractor is PdfSharpTextExtractor in this library, which uses PDFSharp to extract the bytes to convert to text. That implementation doesn't deal well with Unicode text which means when some PDF files are read, the result will be 'junk' strings.
It is certainly possible to replace the IPdfTextExtractor using your own composer like
composition.RegisterUnique<IPdfTextExtractor, MyCustomSharpTextExtractor>();
The iTextSharp library deals with Unicode in a better way but is a paid for license. If you wish to use iTextSharp or another PDF library you can swap out the IPdfTextExtractor with your own implementation.