PDF indexes and multisearchers
If you want to index PDF files and search for them you will need to use the UmbracoExamine.Pdf extension package.
Installation
Install with NuGet: dotnet add package Umbraco.ExaminePDF
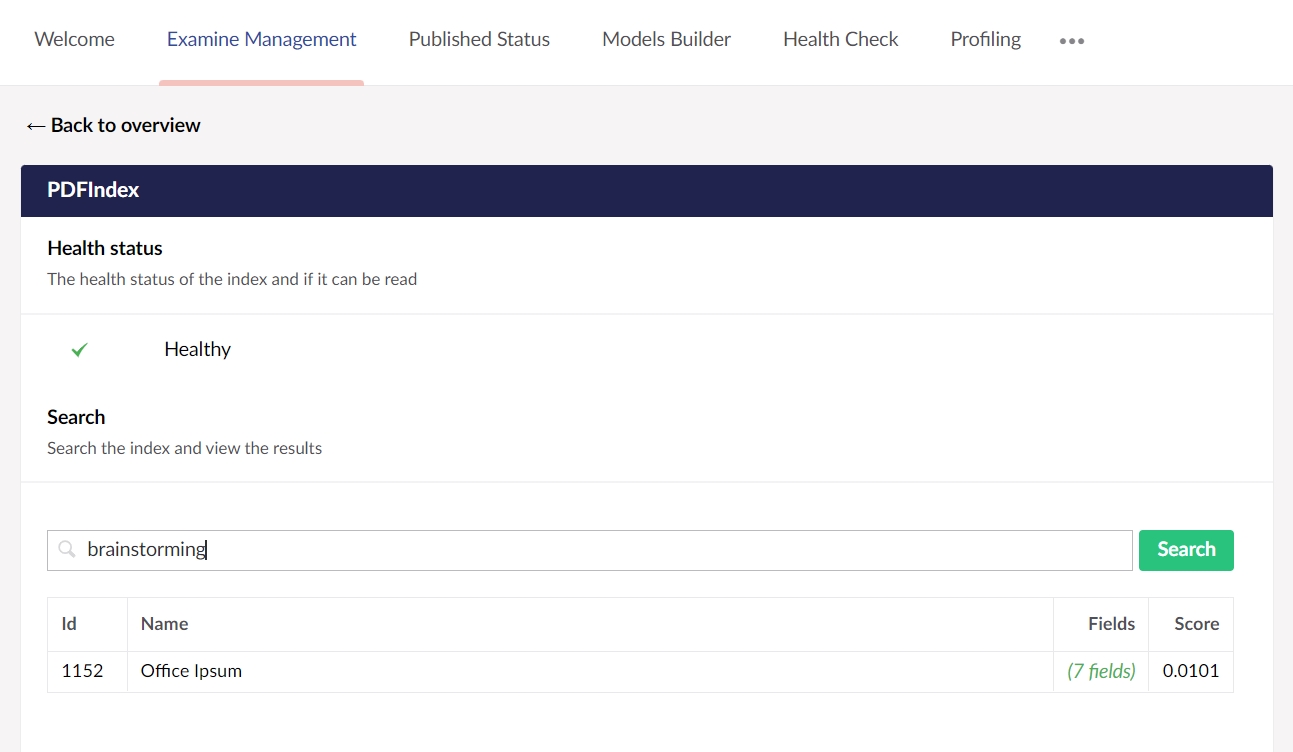
This will create a new Examine index called "PDFIndex", which will appear in "Examine Management" dashboard under the "Settings" section. Using this index you can start searching the contents of any PDF files uploaded to the media section.
Multi-index searchers
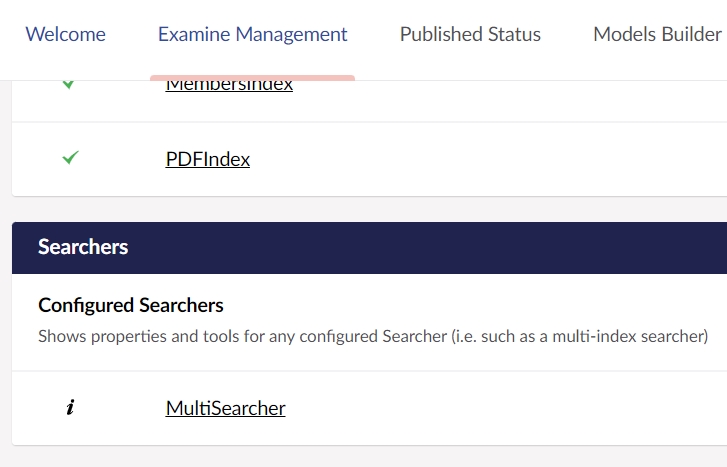
A multi-index searcher is a searcher that can search multiple indexes. This can be helpful when you for example want to search both the external and internal indexes. You can register a multi-index searcher with the ExamineManager on startup like:
With this approach, the multi-index searcher will show up in the "Examine Management" dashboard.
The multi-index searcher can be resolved in code from the ExamineManager like this:
The implementation of IPdfTextExtractor is PdfSharpTextExtractor in this library, which uses PDFSharp to extract the bytes to convert to text. That implementation doesn't deal well with Unicode text which means when some PDF files are read, the result will be 'junk' strings.
It is certainly possible to replace the IPdfTextExtractor using your own composer like
composition.RegisterUnique<IPdfTextExtractor, MyCustomSharpTextExtractor>();
The iTextSharp library deals with Unicode in a better way but is a paid for license. If you wish to use iTextSharp or another PDF library you can swap out the IPdfTextExtractor with your own implementation.
Last updated